AFTER I’VE JOINED THE PROJECT – NEXT STEPS
Many
newly-acquired members don’t know what
to do next after they just cross the gate of our project. Therefore, I will
come up with some basic tutorial.
I will provide a guidance about:
1. Adding information about your earliest known paternal ancestor.
2. Adding location of your earliest known paternal ancestor.
3. Checking your placement in “DNA Results” section (entry Part TWO )
4. Basic understanding of categories you will fall into (entry Part THREE )
5. Ordering single-SNPs, SNP Packs or Big Y, quick comparison (entry part FOUR – coming soon)
I will provide a guidance about:
1. Adding information about your earliest known paternal ancestor.
2. Adding location of your earliest known paternal ancestor.
3. Checking your placement in “DNA Results” section (entry Part TWO )
4. Basic understanding of categories you will fall into (entry Part THREE )
5. Ordering single-SNPs, SNP Packs or Big Y, quick comparison (entry part FOUR – coming soon)
First two
steps can be easily done by administrators. Just send us information through
e-mail, post on Activity Feed etc. etc.
Ad.1 – INFORMATION ABOUT EARLIEST KNOWN PATERNAL ANCESTOR
When you take a look at your “Matches” list, many of your hypothetical male kinsmen are just blank, like this:
Ad.1 – INFORMATION ABOUT EARLIEST KNOWN PATERNAL ANCESTOR
When you take a look at your “Matches” list, many of your hypothetical male kinsmen are just blank, like this:

Irritating,
isn’t it? Many of you are responsible of it, often unintentionally.
FTDNA isn’t too user-friendly, so some of you may have no idea that your matches see NOTHING, beside name and surname of yourself.
Even worse situation is possible, when name and surname belongs to a person that manages certain kit, for example of his/her maternal uncle. In such case, combined with lack of information about earliest known paternal ancestor, your match will not only know NOTHING but also will be MISLEAD.
To picture it - they will see TOM JONES as a contact person and no-one listed as an earliest known paternal ancestor, whereas result actually belongs to ERIC SMITH. SMITH matches won’t contact JONES, because they will think that JONES was the one who got tested and they are interested only in SMITH matches.
FTDNA isn’t too user-friendly, so some of you may have no idea that your matches see NOTHING, beside name and surname of yourself.
Even worse situation is possible, when name and surname belongs to a person that manages certain kit, for example of his/her maternal uncle. In such case, combined with lack of information about earliest known paternal ancestor, your match will not only know NOTHING but also will be MISLEAD.
To picture it - they will see TOM JONES as a contact person and no-one listed as an earliest known paternal ancestor, whereas result actually belongs to ERIC SMITH. SMITH matches won’t contact JONES, because they will think that JONES was the one who got tested and they are interested only in SMITH matches.
OK, I want to check whether everything is fine.
Log in and
move your mouse to the right top, as shown below.
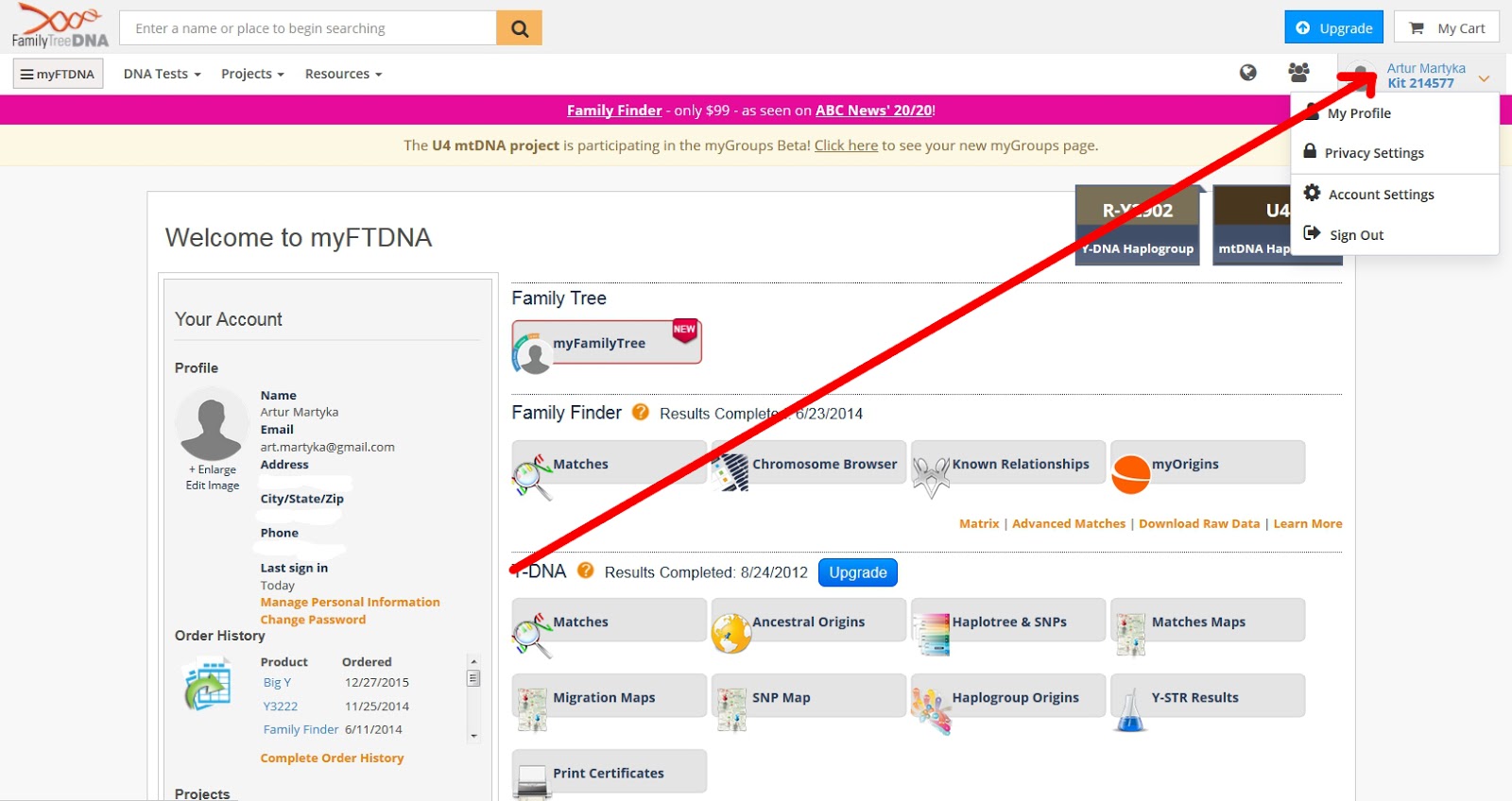
Now, it’s irrelevant whether you click on “My profile”, “Account Settings” or “Privacy Settings”. Click on any of these...then click on "Genealogy" and choose "Most Distant Ancestors".


In this
case, we have no information. Let’s add it. Don't forget to save all of this.

Now, when
the information is saved, we can proceed to the next step.
Ad.2 -
LOCATION OF YOUR EARLIEST KNOWN PATERNAL ANCESTOR
It is also highly important, because it shows to your matches whether your sample is geographically close or from particularly interesting location. It also allows us, administrators, to get an idea about the distribution of various subclades od R1a.
You can start just from where you ended inserting information about earliest known paternal ancestor.





Next...
Sometimes there are many villages or towns with the same names. If you aren't sure, ask administrator or search by Latitude and Longitude. I feel competent about Polish and German placenames.Next...you can change placename if it's name was switched in tides of history, to original one (for instance). It doesn't apply in my case.




Be happy
with your pin! I hope that your matches will be happy as well :).


{kind=link}